Recently, Masked Diffusion Models (MDMs) have shown promising potential across vision, language, and cross-modal generation. However, a notable discrepancy exists between their training and inference procedures. In particular, MDM inference is a multi-step, iterative process governed not only by the model itself but also by various schedules that dictate the token-decoding trajectory (e.g., how many tokens to decode at each step). In contrast, MDMs are typically trained using a simplified, single-step BERT-style objective. This simplification fundamentally disconnects the training paradigm from the trajectory-level nature of inference, leaving the inference schedules never optimized during training.
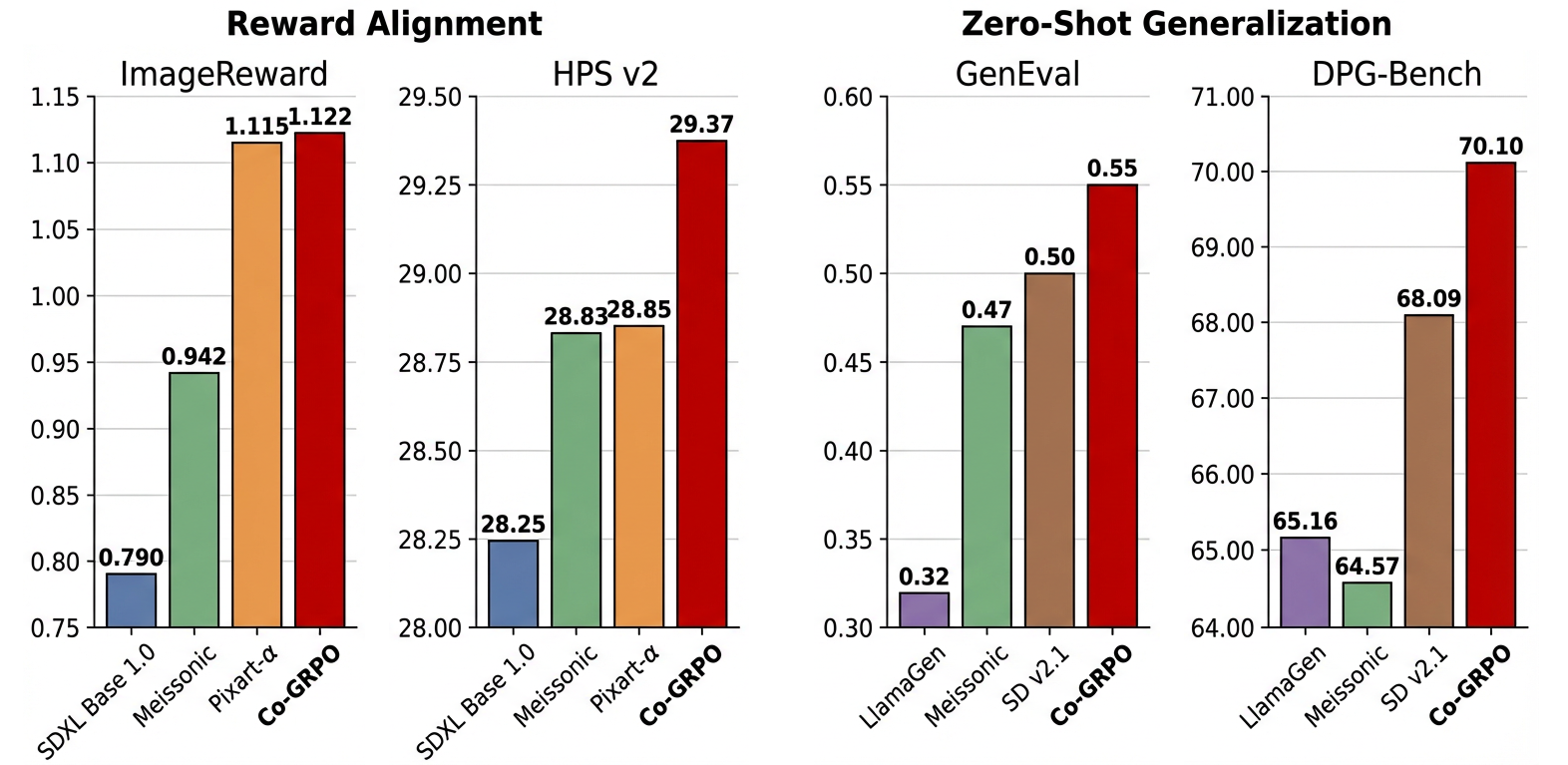
In this paper, we introduce Co-GRPO, which reformulates MDM generation as a unified Markov Decision Process (MDP) that jointly incorporates both the model and the inference schedule. By applying Group Relative Policy Optimization at the trajectory level, Co-GRPO cooperatively optimizes model parameters and schedule parameters under a shared reward, without requiring costly backpropagation through the multi-step generation process. This holistic optimization aligns training with inference more thoroughly and substantially improves generation quality. Empirical results across four benchmarks—ImageReward, HPS, GenEval, and DPG-Bench—demonstrate the effectiveness of our approach.